Returning back home. I get this buzz on my phone. Turns out it’s an email from Linode. Daym. I thought was I billed already?

Trust me on this, I was really not sure what to do of this for the first two minutes when I read the email.
I opened the Linode admin panel to check out what was my server up to. And the CPU graph had jumped off the hooks.
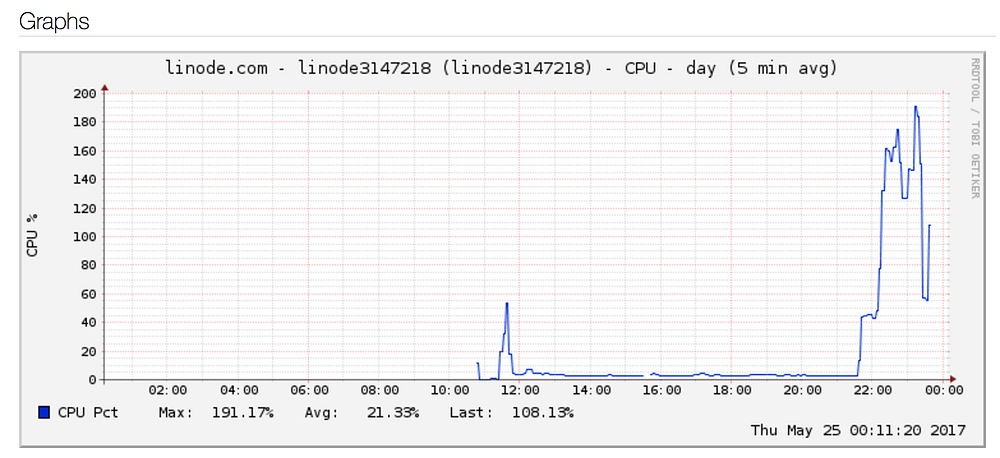
Same was the case with the network graph
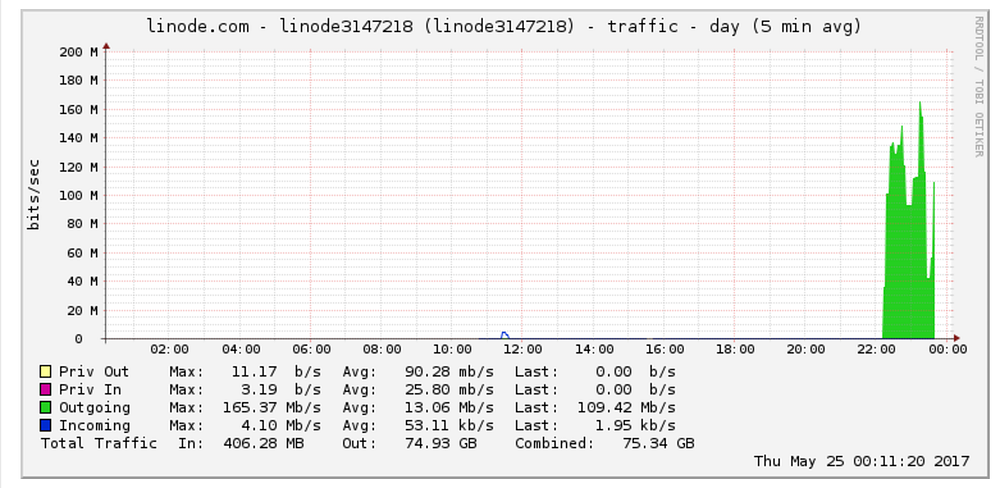
Looking at the network log’s suggested a high amount of outbound traffic coming from my server, further cementing the Linode support ticket that I got.
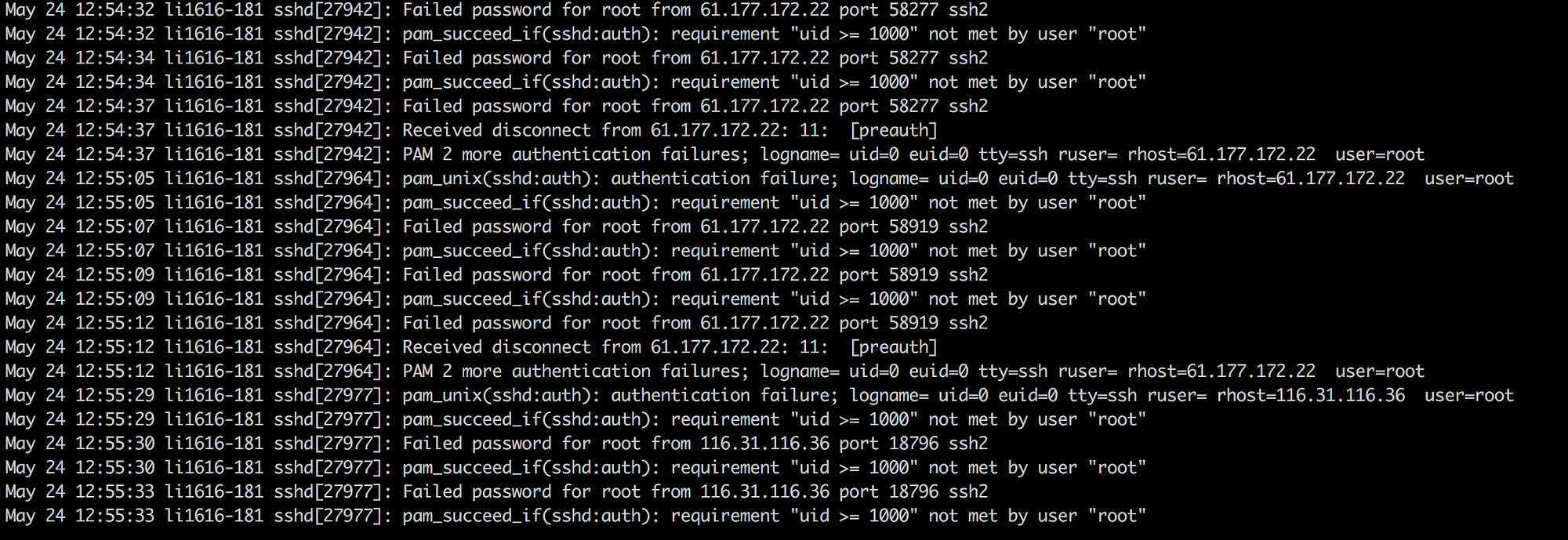
I ssh’d inside my server to see what was going on.

I will be damned. I don’t remember sleep typing my password continuously for that long!
Let me tell you, you don’t do a cat /var/log/secure at this point as the file would just be spit continously at you with no end of stopping.
Did head (even a tail can do) to it. Going through the start of the file, everything was fine until I started to see the extremely less epoch time between two failed attempts. This confirmed my hunch that some script kiddie was trying to brute force through the root user login.
I know, I should have disabled root login at the start and used ssh-keys to access my server. But I just delayed it to be done the next day. My fault.
The logical thing now would be to startiptables(or)ufwand block outbound traffic as well as inbound except required stuff. Then take all the logs and look at them.
yum install breaks

Now I am pretty sure most linux distrbutions, Ubuntu for example ships with ufw by default. An SELinux like centOS not shipping ufw cannot be remotely possible. My hunch was that the perpetrator must have removed it altogether.
No problemo, I could do a yum install ufw right?
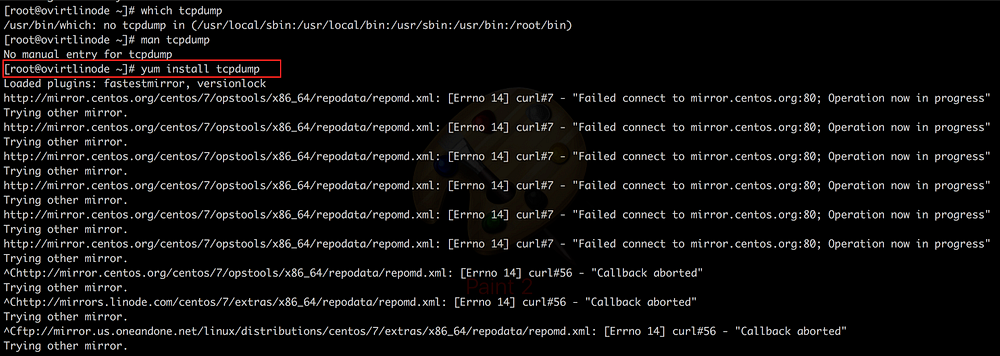
I try installing it and there are constant timeouts on the network calls being made by the server to the mirrors holding the package. Same is the case with other packages like strace, tcpdump et al.

The connection is really sluggish even though I am on a network having very less latency.
when ufw fails go back to good old iptables
ufw stands for uncomplicated firewall. So that you don’t have to directly deal with the low level intricacies
With ufw, for blocking all incoming traffic from a given IP address would have been as simple as doing a
$ sudo ufw deny from <ip-address>
But since I don’t have it, falling back to iptables.
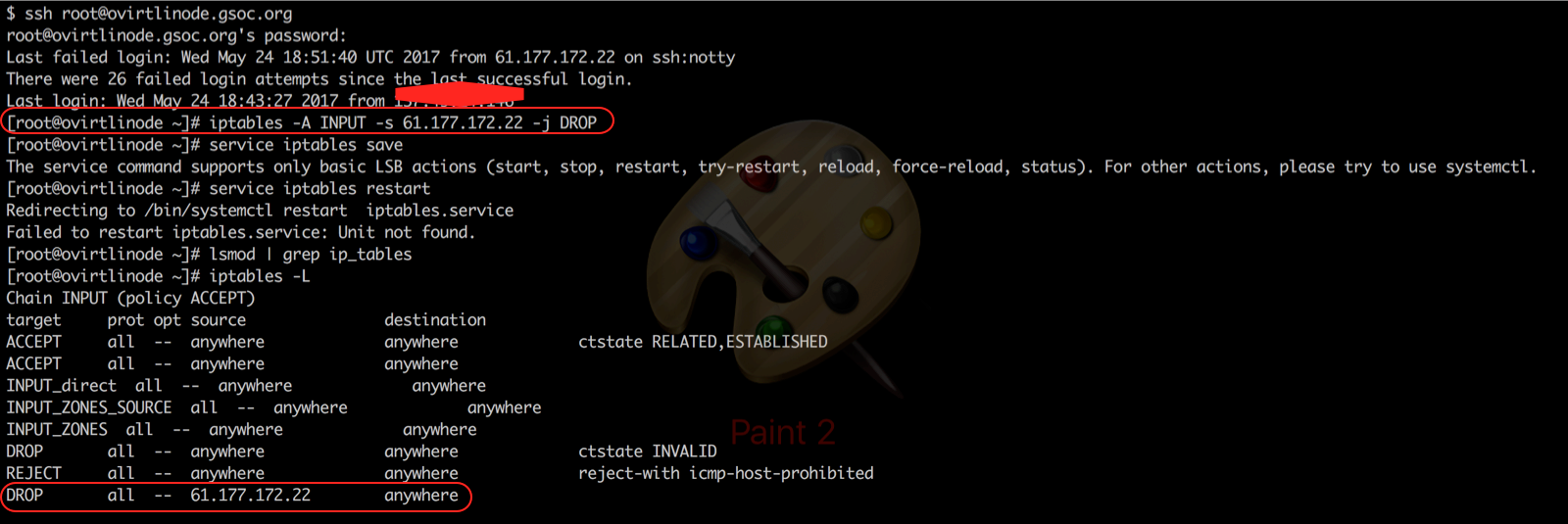
Checking all outgoing requests/connections from the server
For that I did a $ netstat -nputw
lists all UDP (u), TCP (t) and RAW (w) outgoing connections (not using l or a) in a numeric form (n, prevents possible long-running DNS queries) and includes the program (p) associated with that.
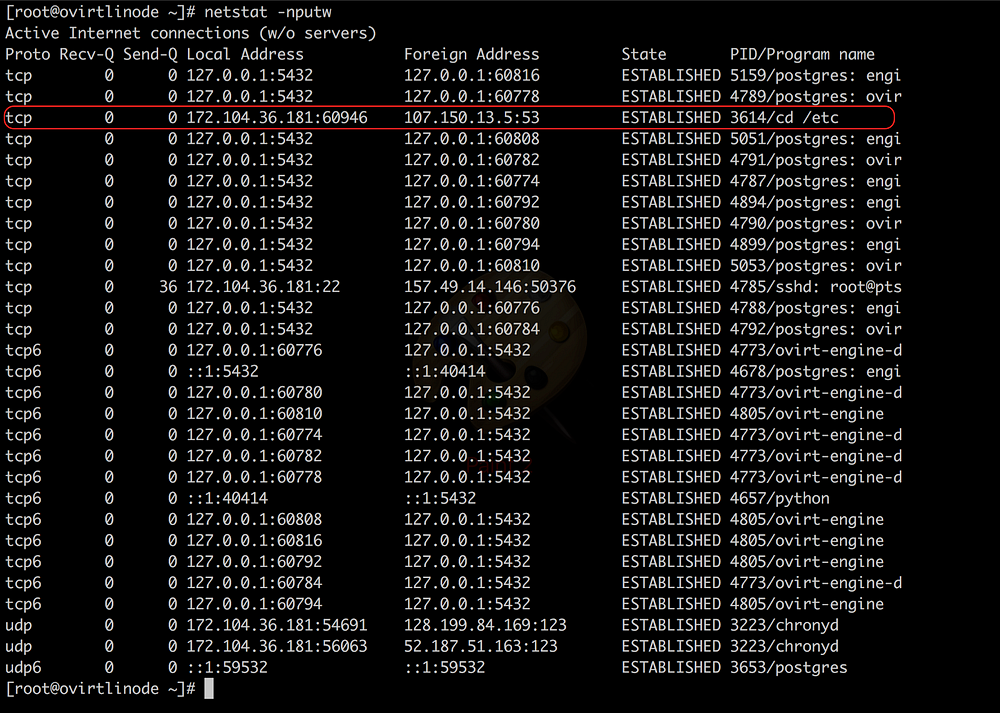
What has a cd command got to do with making network connections?
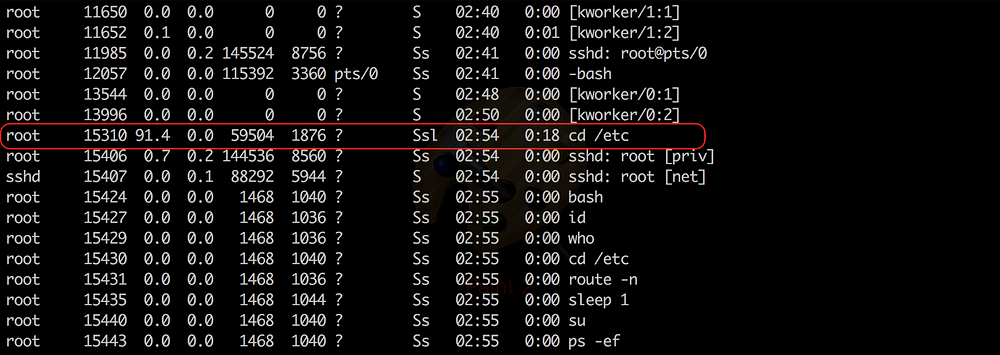
Did a $ ps aux to check all the system processes and the thing was standing out here too
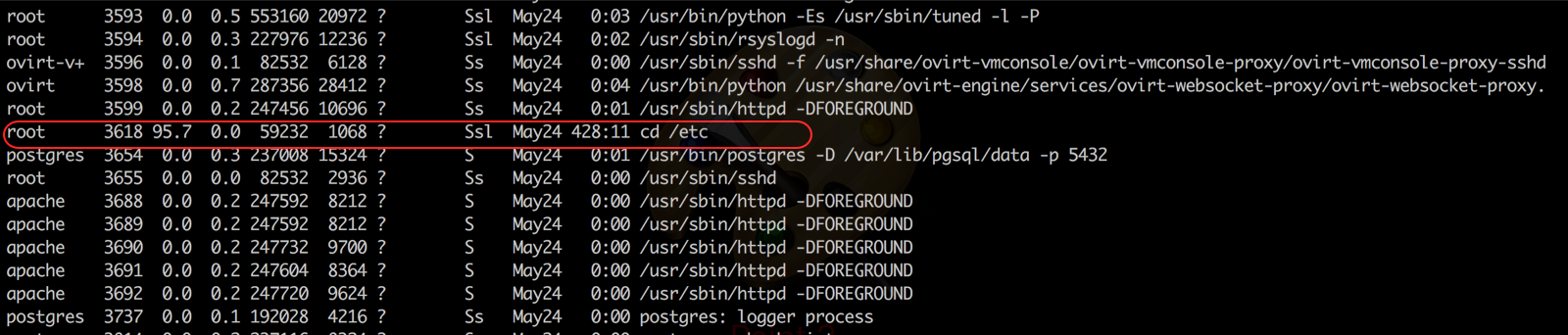
It was taking up 95% of the whole CPU! When was the last time you saw a coreutil doing that?
Digging down further, I wanted to see what were the files being opened by our, at this point I may say modified cd program
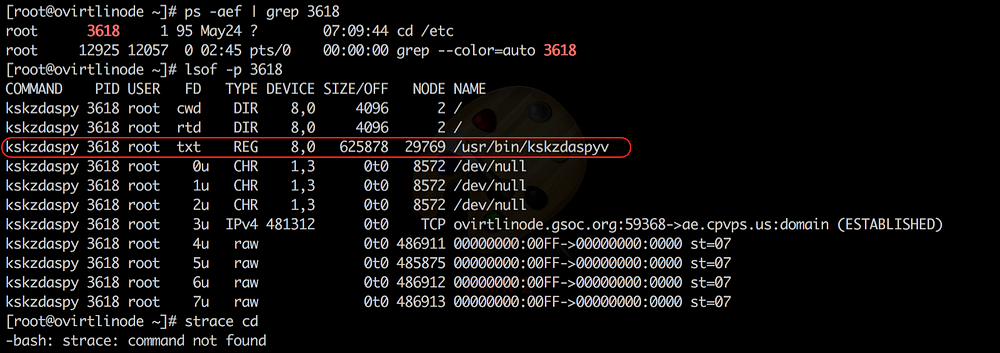
The perpetrator had been running his malicious program under /usr/bin which obviously meant he did gain root access to my server. There was no other way I could think of, through which the perpetrator could have placed it under /usr/bin otherwise.
If you feel, someone else too is logged in, you can easily check that by doing a
$ netstat -nalp | grep “:22″
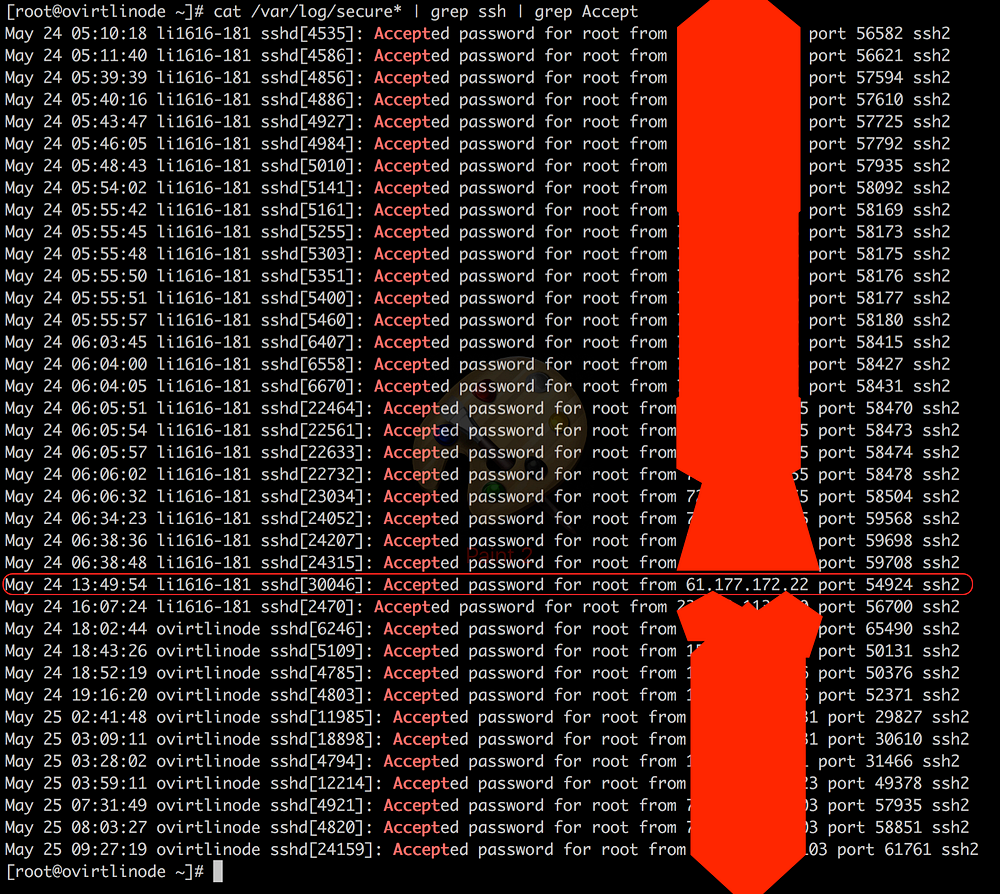
To double check that he did get in, I ran a
$ cat /var/log/secure* | grep ssh | grep Accept
And not so surprisingly,
At this point I don’t have anything like strace or gdb to it to see what this program is doing, as mentioned earlier the inability do install anything using yum through the network.
Compiling from source?
wget was no where to be found!
I could only think of killing the process once and see what happens then. I do a $ kill -9 3618 to kill the process and check ps aux again looking for the particular program only to find it back again as a new process
Conjuring 3
Again killing it and checking the processes. This time I don’t see it.
But I was wrong, looks like there is another process hogging CPU in a similar fashion like cd was doing.
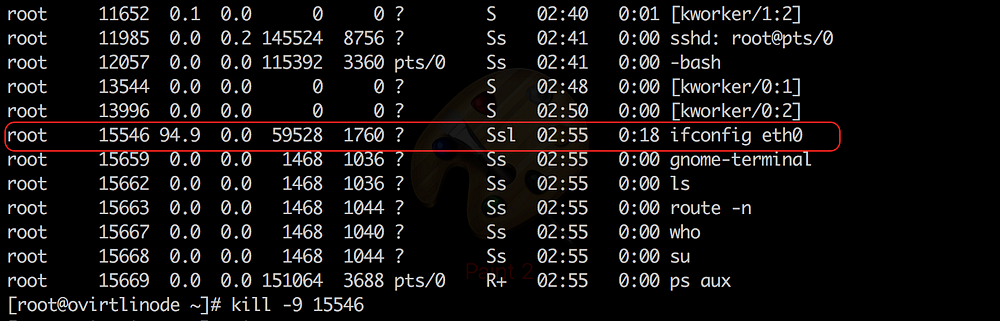
Tbh, this was bat shoot crazy stuff for me. And I was feeling the adrenaline pump. Sleep was something I lost completely even though it was some 3a.m. in the morning. This crap was way too exciting to be left over to be done in the morning!
I check ps aux twice just to double check if there anything in the lines of what happened. And there is nothing this time to send a SIG KILL to.
Relief?
I try installing packages through yum and it’s the same old story of network-timeout.
You might also be wondering why I did not check bash history. Trust me, it was clean! I could only see the things which I had typed away. Whatever it was, it was smart. But I guess this is just the basic stuff of not leaving anything behind.
nmap away all the things
Cause why not?
Ran a quick scan on the server using
$ sudo nmap ovirtlinode.gsoc.orgStarting Nmap 7.40 ( https://nmap.org ) at 2017-05-25 14:35 IST
Nmap scan report for ovirtlinode.gsoc.org
Host is up (0.035s latency).
Not shown: 978 filtered ports
PORT STATE SERVICE
22/tcp open ssh
25/tcp closed smtp
80/tcp open http
113/tcp closed ident
179/tcp closed bgp
443/tcp open https
1723/tcp closed pptp
2000/tcp closed cisco-sccp
2222/tcp open EtherNetIP-1
5432/tcp open postgresql
6000/tcp closed X11
6001/tcp closed X11:1
6002/tcp closed X11:2
6003/tcp closed X11:3
6004/tcp closed X11:4
6005/tcp closed X11:5
6006/tcp closed X11:6
6007/tcp closed X11:7
6009/tcp closed X11:9
6025/tcp closed x11
6059/tcp closed X11:59
6100/tcp open synchronet-db
Checking the UDP connections
$ sudo nmap -sS -sU -T4 -A -v ovirtlinode.gsoc.org
Starting Nmap 7.40 ( https://nmap.org ) at 2017-05-25 14:37 IST
NSE: Loaded 143 scripts for scanning.
NSE: Script Pre-scanning.
Initiating NSE at 14:37
Completed NSE at 14:37, 0.00s elapsed
Initiating NSE at 14:37
Completed NSE at 14:37, 0.00s elapsed
Initiating Ping Scan at 14:37
Scanning ovirtlinode.gsoc.org (172.104.36.181) [4 ports]
Completed Ping Scan at 14:37, 0.01s elapsed (1 total hosts)
Initiating SYN Stealth Scan at 14:37
Scanning ovirtlinode.gsoc.org (172.104.36.181) [1000 ports]
Discovered open port 80/tcp on 172.104.36.181
Discovered open port 443/tcp on 172.104.36.181
Discovered open port 22/tcp on 172.104.36.181
Discovered open port 6100/tcp on 172.104.36.181
Discovered open port 5432/tcp on 172.104.36.181
Discovered open port 2222/tcp on 172.104.36.181
Completed SYN Stealth Scan at 14:37, 4.22s elapsed (1000 total ports)
Initiating UDP Scan at 14:37
Scanning ovirtlinode.gsoc.org (172.104.36.181) [1000 ports]
Completed UDP Scan at 14:37, 4.19s elapsed (1000 total ports)
Initiating Service scan at 14:37
Did not get much out of it.
So this brings me to the moment where I see the attack vector which was placed by the perpetrator becomes dormant. I did not see any other activity which would wry my attention again.
I let my server run for the night (stupid call but I was just plain old curious) to check in the morning what was the status.
Turned out there still had been a fair amount of outbound calls being made during that time.
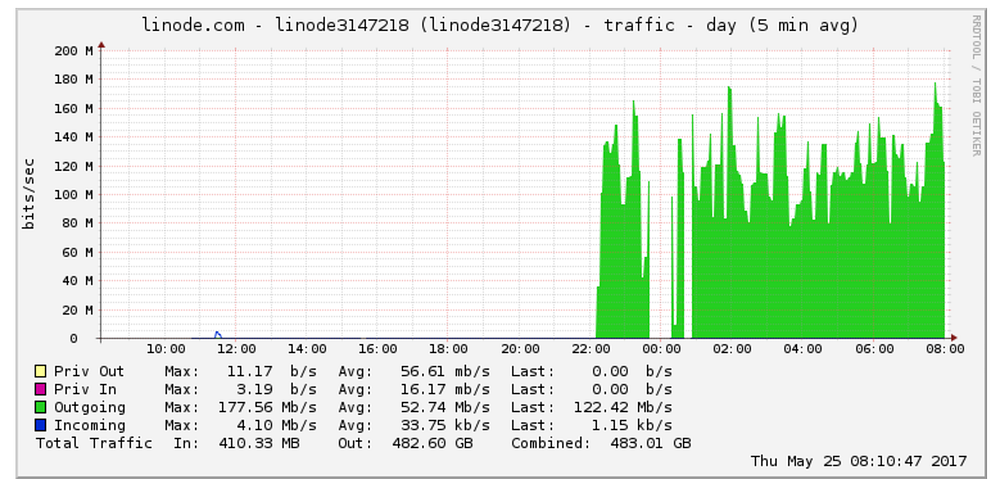
The CPU graph resonated the same
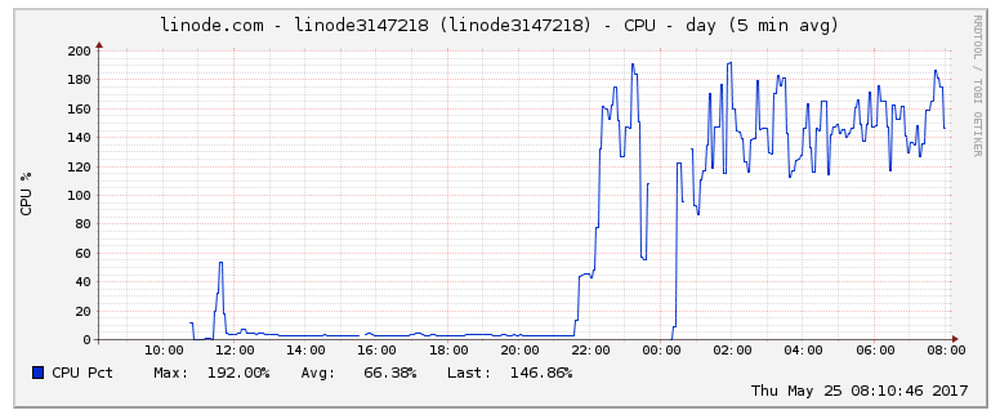
I turned off the server for a brief period of time after this. The CPU graphs can be seen below during that period.

There were no outbound network calls after that.
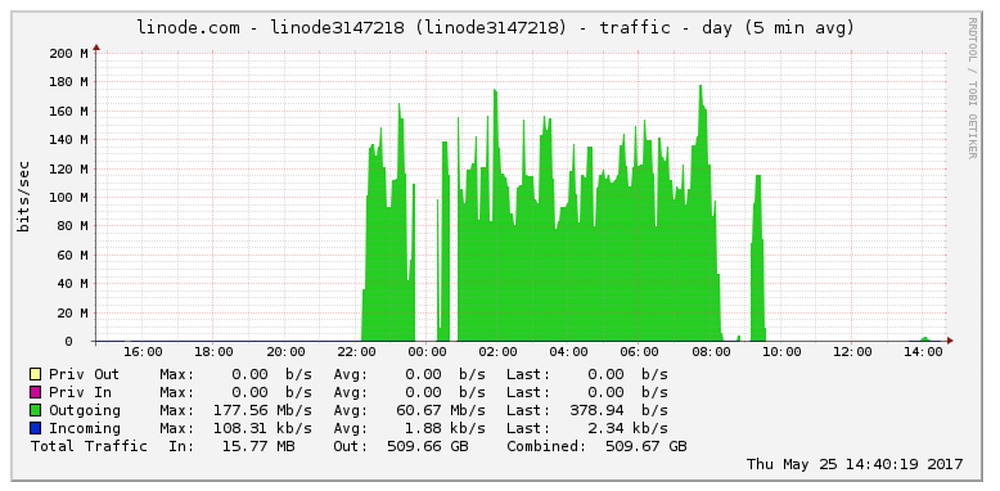
Aftermath
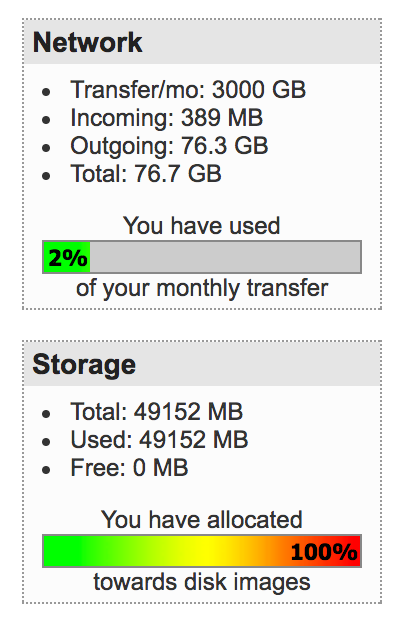
I turned off the server for good. There’s no going back to it. I will be rebuilding the image to it.
It happened to have my public key on the server. This is not something one should immediately worry about. Going from public key to private key is exceptionally hard; that’s how public key cryptography works. (By “exceptionally” I mean that it’s designed to be resistant to well-funded government efforts; if it keeps the NSA from cracking you, it’ll be sure good enough for stopping your average joe)
But just to be on the safer side, I regenerated my ssh keys, deleted the old ones at the places it was being used and updated it with the new ones.
Just to be extra sure of everything, I checked the activity logs of the services which did use the older ssh keys. No unusual activities.
Learnings
- disable root password login
The very first thing that I should have done after provisioning the server would have been to do this. This would in fact have stopped the perpetrator from logging in as root and cause any havoc
- obfuscate the port
sshduses
change it to something not common as the default 22 would be known by you as well as the perpetrator.
But thinking that security through obscurity is makes you fail safe. Think again.
security by obscurity is a beginner fail! one thing is to keep secrets and make it harder to exploit, the other is to rely on secrets for security. The financials were doing it for long until they learned it does not work.
It’s better to use known good practices, protocols and techniques than to come with your own, reinventing the wheel and trying to keep it secret. Reverse engineering has been done for everything, from space rockets to smart toasters. It takes usually 30min to fingerprint an OS version aling with libraries no matter how you protect it. Just looking at a ping RTT can identify the OS, for example.
Finally, nobody ever got blamed for using best practices. Yet, if you try to outsmart the system it’ll all be your fault.
- protect ssh with fail2ban
Fail2ban can mitigate this problem by creating rules that automatically alter your iptables firewall configuration based on a predefined number of unsuccessful login attempts. This will allow your server to respond to illegitimate access attempts without intervention from you.
- Use your public key to ssh into the machine instead of password login as suggested.
- Restrict SSH access by source IP address. If you will only be connecting in from a few IPs then you can restrict port 22 access to just those. Most VPS providers allow this through their website (pushed out to their edge routers etc)
- I kept a really easy to guess, dictionary based password. I have to admit it, this is simply the stupidest thing one can do. And yes, I did it. My only reasoning for doing that was that this was a throwaway server, but that makes up for no excuse for not following security practices.
SO KEEP A STRONG PASSWORD! Even though there is a brute force attack on your server, it is relatively very hard to crack the password if you keep a strong one.
Bruce has a nice essay about the subject here. Won’t repeat what he has said so take a look at it.
Research suggests that adding password complexity requirements like upper case/numbers/symbols cause users to make easy to predict changes and cause them to create simpler passwords overall due to being harder to remember.
Also read OWASP’s blog here about what they have to say about passwords
There was a discussion on security exchange too over this.
- Take regular backups/snapshot’s of your server. That way if something funny does happen. You can always restore it to a previous state.
- Some Files which are in the Common Attack Points:
$ ls /tmp -la$ ls /var/tmp -la$ ls /dev/shm -la
Check these to have a look for something which should not be there.
Unluckily, I had already rebooted my server at that point which caused me to lose this info.
- Keep a pristine copy of critical system files (such as ls, ps, netstat, md5sum) somewhere, with an md5sum of them, and compare them to the live versions regularly. Rootkits will invariably modify these files. Use these copies if you suspect the originals have been compromised.
aideortripwirewill tell you of any files that have been modified - assuming their databases have not been tampered with. Configure syslog to send your logfiles to a remote log server where they can’t be tampered with by an intruder. Watch these remote logfiles for suspicious activity- read your logs regularly — use
logwatchorlogcheckto synthesize the critical information. - Know your servers. Know what kinds of activities and logs are normal.
- using tools like chkrootkit to check for rootkits regularly.
Closing notes
How do you know if your Linux server has been hacked?
You don’t!
I know, I know — but it’s the paranoid, sad truth, really ;) There are plenty of hints of course, but if the system was targeted specifically — it might be impossible to tell. It’s good to understand that nothing is ever completely secure.
If your system was compromised, meaning once someone has root on your host, you cannot trust anything you see because above and beyond the more obvious methods like modifying ps, ls, etc, one can simply attack kernel level system calls to subjugate IO itself. None of your system tools can be trusted to reveal the truth.
Simply put, you cant trust anything your terminal tells you, period.
Reprint:https://tosdn.com/learnings-from-analysing-my-compromised-server
No comments:
Post a Comment